Le 1er mai 2024, le ministère des affaires étrangères ukrainien a publié une vidéo sur les réseaux sociaux, présentant leur nouvelle porte parole, Victoria Shi. Celle-ci possède toutefois une particularité : il s’agit d’une avatar générée par intelligence artificielle. D’après plusieurs articles, elle n’est toutefois pas entièrement le produit d’une génération, car elle serait inspirée d’une chanteuse et influenceuse ukrainienne, Rosalie Nombre. De plus, ses propos ne sont pas générés par des modèles de langue, mais ils sont prétendument rédigés par des membres (humains) du gouvernement.
Beaucoup de médias se sont emparés de cette information, qui relate d’une première mondiale, en questionnant ce choix. Néanmoins, nous ne nous attarderons pas sur l’aspect discutable d’utiliser une IA comme porte-parole (le terme anglais spokesPERSON révèle d’autant plus le paradoxe d’un tel choix). Nous souhaitons ici aborder le sujet avec une approche différente, discutant les implications du choix du genre féminin de cette avatar, qui amène une résonance différente que s’il s’agissait d’un homme virtuel.
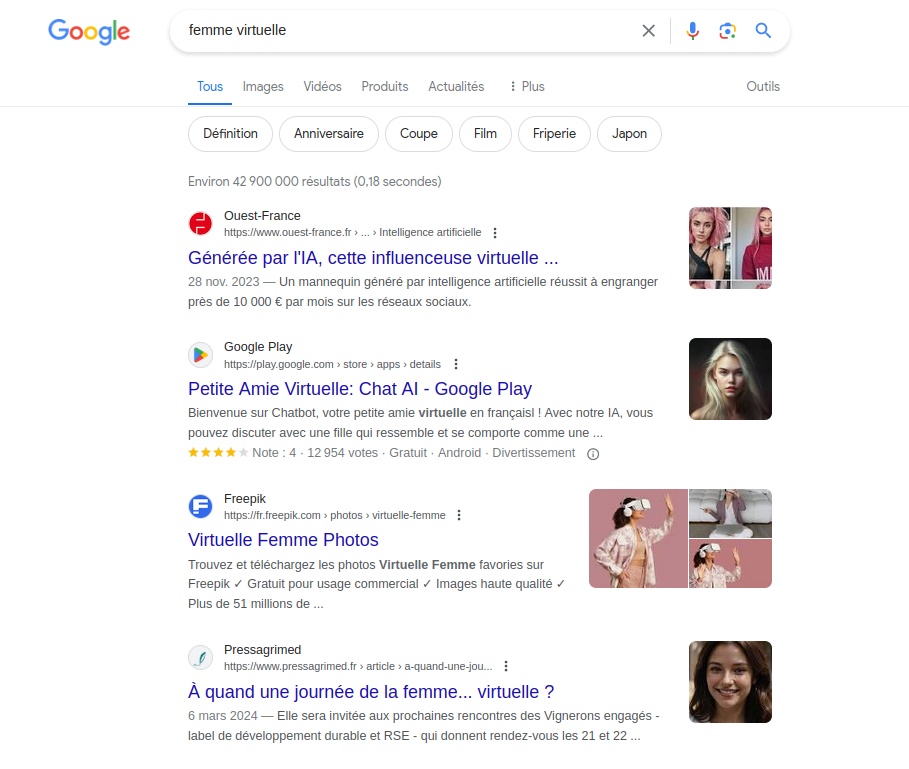
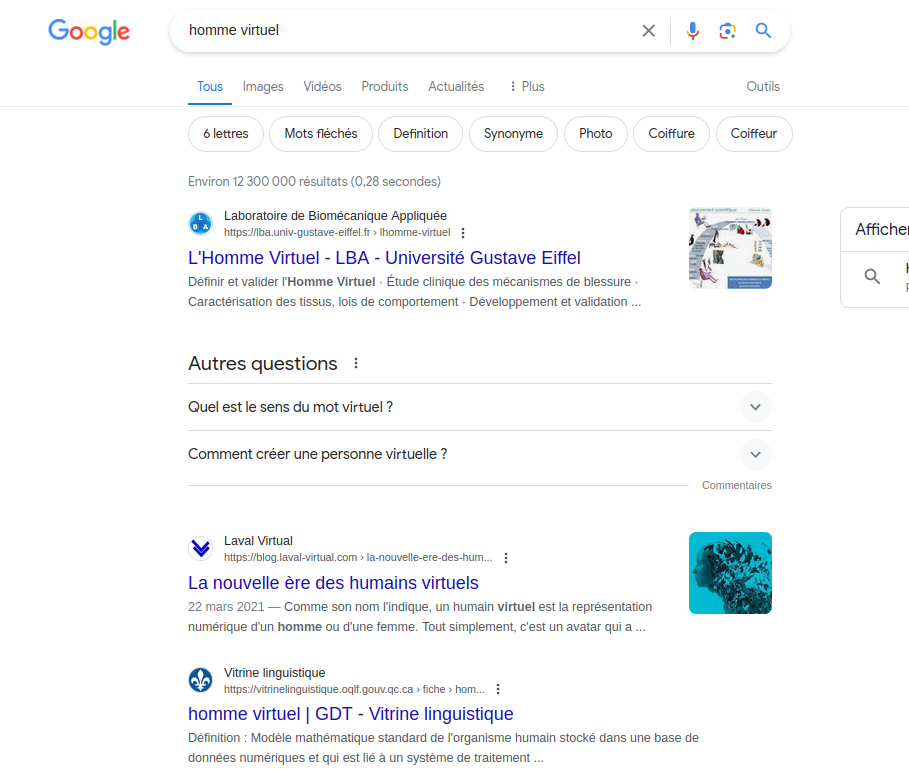
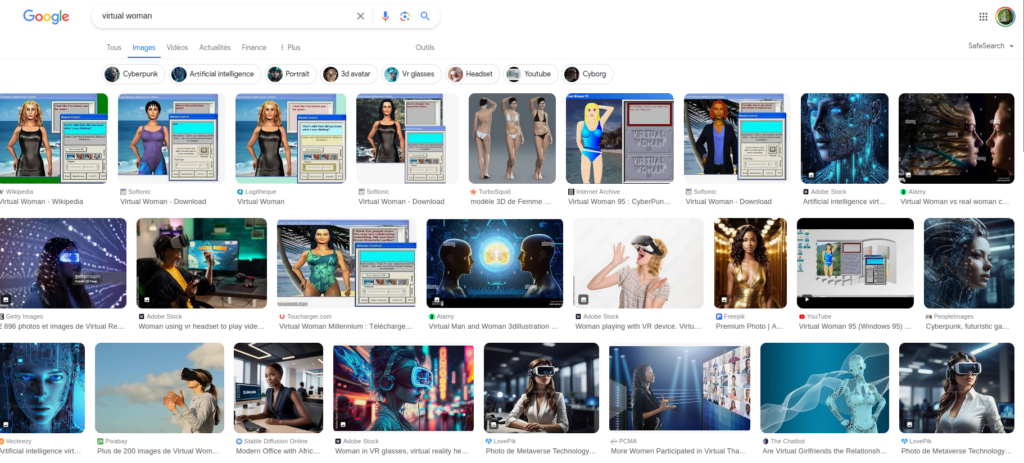
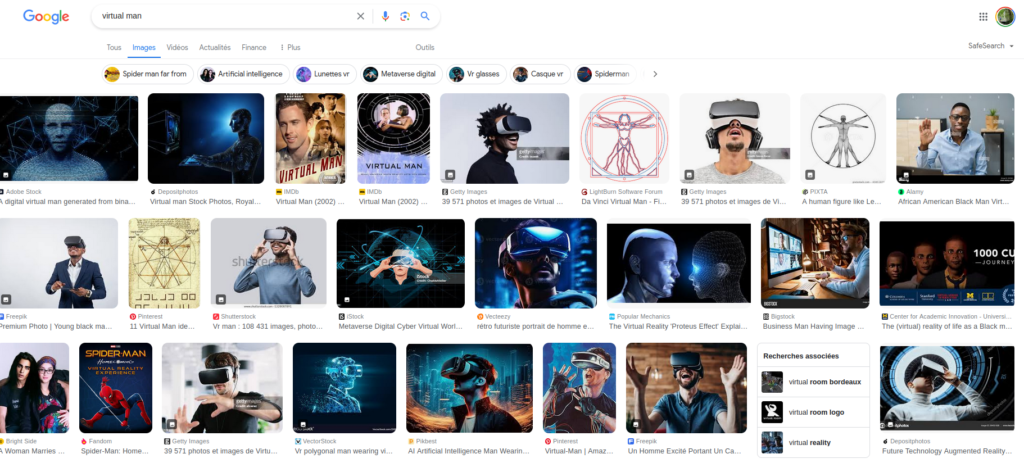
En effet, cette avatar a l’apparence d’une femme et est présentée comme telle (et il est intéressant de noter qu’il n’est pas surprenant que cette IA soit une femme, c’était presque attendu). Le corps féminin est alors utilisé uniquement pour son visuel, son image. C’est d’ailleurs d’autant plus frappant qu’il s’agit du corps d’une femme réelle, mais qui n’a pas été embauchée. Seule son image a été retenue, qu’on utilise comme une façade, une coquille vide à laquelle on fait dire ce que l’on souhaite. Cette utilisation de la féminité n’est pas sans rappeler le cas d’assistants virtuels comme Alexa, Siri ou les voix par défaut de Google Maps et autres GPS, qui avaient déjà posé question [1]. L’apparence féminine est encore une fois utilisée dans sa superficialité, en mettant en avant son caractère rassurant et attrayant, ravivant ainsi des stéréotypes de genre. Cette avatar agit ainsi comme une poupée, littéralement contrôlée par d’autres individus, dont on peut supposer qu’ils sont majoritairement des hommes, atteignant ainsi le fantasme sexiste d’une femme complètement soumise et passive, sans personnalité, agentivité ou volonté propre, et entièrement manipulée par des hommes. La notion de « femme virtuelle » évoque d’ailleurs des associations avec des IA féminines sexualisées, conçues dans une optique de «séduction», voire d’objets sexuels. (Une simple recherche sur Internet confirme cette intuition – voir captures en fin d’article.)
On peut même mener la réflexion plus loin, en se demandant s’il s’agit là d’une stratégie pour mettre en avant une certaine diversité, puisqu’il s’agit d’une femme, qui plus est métisse. Cela pourrait remettre en question la notion de quota et de diversité, qui serait dès à présent atteinte par l’utilisation de physiques divers, et non d’individus. Cette observation est à relier au fait que, parmi les 10 précédents porte-paroles du ministère des affaires étrangères, on compte 8 hommes et seulement 2 femmes. Autrement dit, plutôt que d'embaucher une femme réelle, et plus encore, une femme métisse réelle, il a été décidé de la générer. Son apparence est donc utilisée comme un simple outil, pour attirer la sympathie, mais sans impliquer l’existence et l'embauche d’une femme noire réelle. On ne bénéficie ainsi que d’aspects bénéfiques superficiels de la médiatisation d’une femme de couleur, sans pour autant prendre en compte les opinions d’une membre de cette population, sans participer à une forme de progrès social. La diversité et le feminism-washing à leur paroxysme : on utilise l’apparence d’une femme pour se donner bonne image, sans mesurer l’intérêt d’avoir une porte-parole qui serait une femme de couleur réelle.
Références
[1] Nóra Ni Loideain, Rachel Adams. From Alexa to Siri and the GDPR: The gendering of Virtual Personal Assistants and the role of Data Protection Impact Assessments. Computer Law & Security Review, Volume 36, 2020. https://doi.org/10.1016/j.clsr.2019.105366.